Huong Dan Cau Hinh Auto Scale Su Dung Keda Va Prometheus
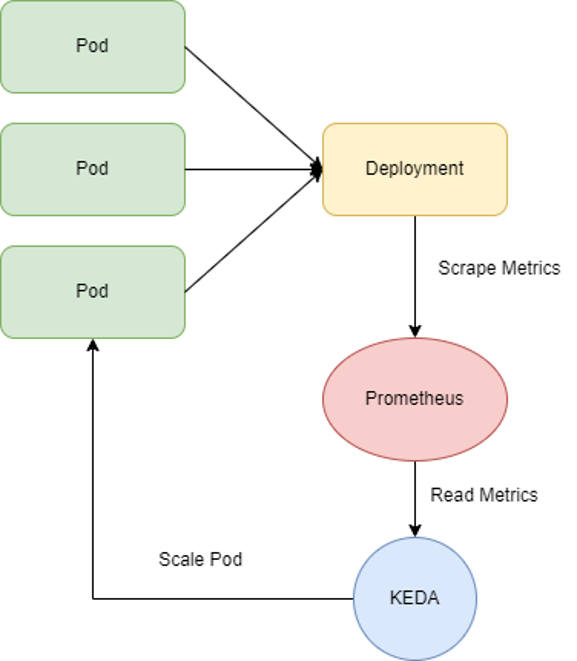
Yêu cầu
- Cụm kubernetes có gắn GPU
- Ứng dụng GPU đang ở trạng thái running
- Đã cài đặt gói kube-prometheus-stack và prometheus-adapter ở dịch vụ FPT App Catalog như docs Hướng dẫn cấu hình Auto Scale cho FPT Kubernetes Engine GPU sử dụng GPU Custom Metric
Các bước cấu hình:
Bước 1: Cài đặt KEDA
- Cách 1: Sử dụng FPT App Catalog Chọn dịch vụ FPT Cloud App Catalog sau đó tìm kiếm KEDA trong Repository fptcloud-catalogs
- Cách 2: Sử dụng helm chart
Copyhelm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install keda kedacore/keda --namespace keda --create-namespace
- Kiểm tra xem các pod của KEDA đã hoạt động bình thường hay chưa
Copykubectl -n keda get pod
CopyNAME READY STATUS RESTARTS AGE
pod/keda-admission-webhooks-54764ff7d5-l4tks 1/1 Running 0 3d
pod/keda-operator-567cb596fd-wx4t8 1/1 Running 0 2d23h
pod/keda-operator-metrics-apiserver-6475bf5fff-8x8bw 1/1 Running 0 2d14h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/keda-admission-webhooks ClusterIP 100.71.2.54 443/TCP 3d2h
service/keda-operator ClusterIP 100.66.228.223 9666/TCP 3d2h
service/keda-operator-metrics-apiserver ClusterIP 100.71.162.181 443/TCP,8080/TCP 3d2h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/keda-admission-webhooks 1/1 1 1 3d2h
deployment.apps/keda-operator 1/1 1 1 3d2h
deployment.apps/keda-operator-metrics-apiserver 1/1 1 1 3d2h
NAME DESIRED CURRENT READY AGE
replicaset.apps/keda-admission-webhooks-54764ff7d5 1 1 1 3d2h
replicaset.apps/keda-operator-567cb596fd 1 1 1 3d2h
replicaset.apps/keda-operator-metrics-apiserver-6475bf5fff 1 1 1 3d2h
Bước 2: Kiểm tra prometheus đã có các metric GPU hay chưa
Copykubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 | jq -r . | grep DCGM
Copy"name": "namespaces/DCGM_FI_DEV_POWER_USAGE",
"name": "namespaces/DCGM_FI_DEV_FB_USED",
"name": "namespaces/DCGM_FI_DEV_PCIE_REPLAY_COUNTER",
"name": "pods/DCGM_FI_DEV_XID_ERRORS",
"name": "namespaces/DCGM_FI_PROF_GR_ENGINE_ACTIVE",
"name": "namespaces/DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION",
"name": "pods/DCGM_FI_PROF_DRAM_ACTIVE",
"name": "jobs.batch/DCGM_FI_DEV_POWER_USAGE",
"name": "jobs.batch/DCGM_FI_DEV_SM_CLOCK",
"name": "namespaces/DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL",
"name": "pods/DCGM_FI_DEV_POWER_USAGE",
"name": "jobs.batch/DCGM_FI_DEV_MEM_CLOCK",
"name": "jobs.batch/DCGM_FI_DEV_FB_USED",
"name": "namespaces/DCGM_FI_DEV_FB_FREE",
"name": "jobs.batch/DCGM_FI_PROF_GR_ENGINE_ACTIVE",
"name": "pods/DCGM_FI_DEV_MEMORY_TEMP",
"name": "pods/DCGM_FI_DEV_FB_FREE",
"name": "pods/DCGM_FI_DEV_MEM_CLOCK",
"name": "pods/DCGM_FI_PROF_GR_ENGINE_ACTIVE",
"name": "pods/DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL",
"name": "pods/DCGM_FI_PROF_PIPE_TENSOR_ACTIVE",
"name": "jobs.batch/DCGM_FI_DEV_MEMORY_TEMP",
"name": "namespaces/DCGM_FI_DEV_MEM_CLOCK",
"name": "jobs.batch/DCGM_FI_DEV_XID_ERRORS",
"name": "namespaces/DCGM_FI_DEV_VGPU_LICENSE_STATUS",
"name": "jobs.batch/DCGM_FI_DEV_VGPU_LICENSE_STATUS",
"name": "pods/DCGM_FI_DEV_GPU_TEMP",
"name": "jobs.batch/DCGM_FI_PROF_PIPE_TENSOR_ACTIVE",
"name": "pods/DCGM_FI_DEV_PCIE_REPLAY_COUNTER",
"name": "pods/DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION",
"name": "jobs.batch/DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION",
"name": "pods/DCGM_FI_DEV_FB_USED",
"name": "pods/DCGM_FI_DEV_VGPU_LICENSE_STATUS",
"name": "namespaces/DCGM_FI_DEV_MEMORY_TEMP",
"name": "jobs.batch/DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL",
"name": "namespaces/DCGM_FI_DEV_SM_CLOCK",
"name": "namespaces/DCGM_FI_PROF_PIPE_TENSOR_ACTIVE",
"name": "namespaces/DCGM_FI_DEV_GPU_TEMP",
"name": "jobs.batch/DCGM_FI_DEV_GPU_TEMP",
"name": "namespaces/DCGM_FI_PROF_DRAM_ACTIVE",
"name": "namespaces/DCGM_FI_DEV_XID_ERRORS",
"name": "jobs.batch/DCGM_FI_DEV_FB_FREE",
"name": "pods/DCGM_FI_DEV_SM_CLOCK",
"name": "jobs.batch/DCGM_FI_DEV_PCIE_REPLAY_COUNTER",
"name": "jobs.batch/DCGM_FI_PROF_DRAM_ACTIVE",
Bước 3: Tạo ScaledObject để chỉ định autoscale cho Ứng dụng
- Manifest
CopyapiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: scaled-object
spec:
scaleTargetRef:
name: gpu-test
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-kube-prometheus-prometheus.prometheus.svc.cluster.local:9090
metricName: engine_active
query: sum(DCGM_FI_PROF_GR_ENGINE_ACTIVE{modelName="NVIDIA A30", container="gpu-test"}) / count(DCGM_FI_PROF_GR_ENGINE_ACTIVE{modelName="NVIDIA A30", container="gpu-test"})
threshold: '0.8'
- name : Tên Deployment GPU ở ví dụ là
gpu-test - serverAddress: Endpoint của Prometheus server ở ví dụ là
http://prometheus-kube-prometheus-prometheus.prometheus.svc.cluster.local:9090 - query : Câu lệnh PromQL để tìm ra giá trị dựa vào đó tiến hành autoscale, ở trên ví dụ là tìm các giá trị trung bình của biến
DCGM_FI_PROF_GR_ENGINE_ACTIVE - threshold : giá trị đạt ngưỡng để bắt đầu active autoscale, ở ví dụ là
0.8
Như vậy như ví dụ trên, mỗi khi có giá trị trung bình củaDCGM_FI_PROF_GR_ENGINE_ACTIVE lớn hơn 0.8 thì ScaledObject sẽ thực hiện scale các pod của Deployment name gpu-test.
Sau khi tạo ScaledObject, deployment sẽ tự động scale về 0, như vậy là đã cấu hình thành công.