Trien Khai Ung Dung Su Dung Gpu Tren Kubernetes
Kubernetes quản lý và sử dụng resources GPU tương tự như sử dụng resources CPU. Tùy vào cấu hình GPU lựa chọn cho Worker Group để khai báo resources GPU cho ứng dụng trên Kubernetes. Chú ý:
- Có thể chỉ định GPU limits mà không cần chỉ định requests do Kubernetes sử dụng limits làm giá trị yêu cầu mặc định.
- Có thể chỉ định cả GPU limits và requests nhưng hai giá trị này phải bằng nhau.
- Không thể chỉ định GPU requests mà không chỉ định limits.
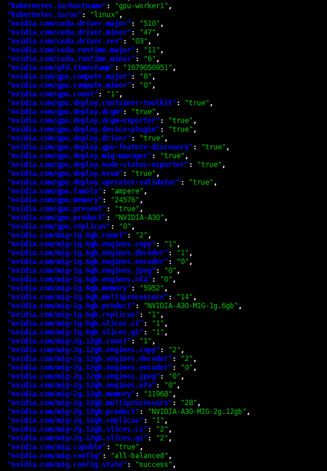
- Kiểm tra cấu hình GPU bằng lệnh sau:
Copykubectl get node -o json | jq ‘.items[].metadata.labels‘
Ví dụ: hình dưới cho thấy worker sử dụng card Nvidia A30, cấu hình strategy: all-balanced, trạng thái: success.
💡 Kiểm tra cấu hình GPU Instance trên worker chưa bằng lệnh sau (ssh vào worker, gõ lệnh):
👉 Ví dụ triển khai ứng dụng sử dụng GPU:
1️⃣ Với sharing mode MIG và strategy: single, tài nguyên GPU được khai báo như sau:
CopyCú pháp:
nvidia.com/gpu: ~~
#Ví dụ:
nvidia.com/gpu: 1
*(Với strategy single, card GPU chia được chia nhỏ thành các instance bằng nhau) ~~
Ví dụ deployment sử dụng GPU single strategy
CopyapiVersion: apps/v1
kind: Deployment
metadata:
name: example-gpu-app
spec:
replicas: 1
selector:
matchLabels:
component: gpu-app
template:
metadata:
labels:
component: gpu-app
spec:
containers:
- name: gpu-container
securityContext:
capabilities:
add:
- SYS_ADMIN
resources:
limits:
nvidia.com/gpu: 1
image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04
command: ["/bin/sh", "-c"]
args:
- while true; do /usr/bin/dcgmproftester11 --no-dcgm-validation -t 1004 -d 300; sleep 30; done
2️⃣ Với sharing mode MIG và mixed, tài nguyên GPU được khai báo như sau:
Copy#Cú pháp:
nvidia.com/: ~~
#Ví dụ:
nvidia.com/mig-1g.6gb: 2
*(Với strategy mixed, card GPU chia được chia nhỏ thành 2 loại instance nên khi khai báo resources cần chỉ rõ loại instance sử dụng) ~~
Ví dụ deployment sử dụng gpu mixed strategy
CopyapiVersion: apps/v1
kind: Deployment
metadata:
name: example-gpu-app
spec:
replicas: 1
selector:
matchLabels:
component: gpu-app
template:
metadata:
labels:
component: gpu-app
spec:
containers:
- name: gpu-container
securityContext:
capabilities:
add:
- SYS_ADMIN
resources:
limits:
nvidia.com/mig-1g.6gb: 1
image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04
command: ["/bin/sh", "-c"]
args:
- while true; do /usr/bin/dcgmproftester11 --no-dcgm-validation -t 1004 -d 300; sleep 30; done
3️⃣ Với none strategy, tài nguyên GPU được khai báo như sau:
Copy#Cú pháp:
nvidia.com/gpu: 1
*(Với none strategy, pod sẽ dùng toàn bộ tài nguyên của một card GPU)
Ví dụ deployment sử dụng gpu none strategy
CopyapiVersion: apps/v1
kind: Deployment
metadata:
name: example-gpu-app
spec:
replicas: 1
selector:
matchLabels:
component: gpu-app
template:
metadata:
labels:
component: gpu-app
spec:
containers:
- name: gpu-container
securityContext:
capabilities:
add:
- SYS_ADMIN
resources:
limits:
nvidia.com/gpu: 1
image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04
command: ["/bin/sh", "-c"]
args:
- while true; do /usr/bin/dcgmproftester11 --no-dcgm-validation -t 1004 -d 300; sleep 30; done
4️⃣ Với sharing mode MPS, tài nguyên GPU được khai báo như sau:
Copy#Cú pháp:
nvidia.com/gpu: ~~
#Ví dụ:
nvidia.com/gpu: 1 ~~
Chú ý: số lượng tài nguyên nvidia.com/gpu một pod request tối đa chỉ bằng 1.