Huong Dan Su Dung Cac Che Do Gpu Sharing
Các chế độ GPU sharing cho phép GPU vật lý được chia sẻ bởi nhiều container nhằm mục đích tối ưu hóa mức độ sử dụng GPU. Sau đây là các chiến lược GPU sharing được chúng tôi hỗ trợ:
| Multi-instance GPU | GPU time-sharing | NVIDIA MPS | |
|---|---|---|---|
| General | GPU be divided and sharing among multiple containers | Each container use GPU in a slice of time | Containers use GPU in parallel |
| Isolation | A GPU be divided in up to seven instances, each instance has its own dedicated compute, memory, bandwidth. Each partition is fully disparated with each other. | Each container accesses the full capacity of the underlying physical GPU by doing context switching between processes running on a GPU. However, time-sharing provides no memory limit enforcement between shared Jobs and the rapid context switching for shared access may introduce overhead. | NVIDIA MPS has limited resource isolation, but gains more flexibility in other dimensions, for example GPU types and max shared units, which simplify resource allocation. |
| Suitable for these workloads | Recommended for workloads running in parallel and that need certain resiliency and QoS. For example, when running AI inference workloads, multi-instance GPU multi-instance GPU allows multiple inference queries to run simultaneously for quick responses, without slowing each other down. | Recommended for bursty and interactive workloads that have idle periods. These workloads are not cost-effective with a fully dedicated GPU. By using time-sharing, workloads get quick access to the GPU when they are in active phases. GPU time-sharing is optimal for scenarios to avoid idling costly GPUs where full isolation and continuous GPU access might not be necessary, for example, when multiple users test or prototype workloads. Workloads that use time-sharing need to tolerate certain performance and latency compromises. | Recommended for batch processing for small jobs because MPS maximizes the throughput and concurrent use of a GPU. MPS allows batch jobs to efficiently process in parallel for small to medium sized workloads. NVIDIA MPS is optimal for cooperative processes acting as a single application. For example, MPI jobs with inter-MPI rank parallelism. With these jobs, each small CUDA process (typically MPI ranks) can run concurrently on the GPU to fully saturate the whole GPU. Workloads that use CUDA MPS need to tolerate the memory protection and error containment limitations. |
| A. Multi instance GPU (MIG) | |||
| Multi instance GPU là tính năng cho phép GPU của bạn được chia ra thành tối đa 7 phần tách rời nhau. Các phần GPU này được gọi là các MIG instance, các MIG instance này hoàn toàn tách biệt với nhau về khả năng tính toán, băng thông, bộ nhớ. | |||
| GPU k8s service của chúng tôi hỗ trợ các MIG profile như sau: | |||
| No. | GPU A100 Profile | Strategy | Number instance |
| --- | --- | --- | --- |
| 1 | all-1g.10gb | single | 7 |
| 2 | all-1g.20gb | single | 4 |
| 3 | all-2g.20gb | single | 3 |
| 4 | all-3g.40gb | single | 2 |
| 5 | all-4g.40gb | single | 1 |
| 6 | all-balanced | mixed | 2 |
| 1 | |||
| 1 | 1g.10gb | ||
| 2g.20gb | |||
| 3g.40gb | |||
| 7 | none with operator | none | 0 |
| 8 | none | none | 0 |
| No. | GPU A30 Profile | Strategy | Number instance |
| --- | --- | --- | --- |
| 1 | all-1g.6gb | single | 4 |
| 2 | all-2g.12gb | single | 2 |
| 3 | all-4g.24gb | single | 1 |
| 4 | all-balanced | mixed | 2 |
| 1 | 1g.6gb | ||
| 2g.12gb | |||
| Ví dụ: Nếu chọn cấu hình strategy single: all-1g.6gb, card GPU A30 trên worker được chia nhỏ thành 4 MIG-devices có tài nguyên GPU bằng ¼ GPU vật lý và 6GB GPU RAM. | |||
| Chú ý: | |||
| ✔ MIG config áp dụng cho tất cả các card gắn trên worker. | |||
| ✔ MIG strategy trên các worker group của cùng cluster phải cùng 1 loại (single/mixed/none). | |||
| ✔ Đối với stragegy “none with Operator”, pod có thể sử dụng 1 GPU devices chứa tài nguyên của toàn bộ GPU. | |||
| ✔ Đối với stragegy “none”, GPU đã được kết nối sẵn vào máy, người dùng có thể tự deploy GPU Operator hoặc GPU device plugin theo cấu hình mong muốn. Khuyến nghị người dùng cần nắm chắc các kiến thức cơ bản về GPU-Sharing trước khi thực hiện strategy này! | |||
| B. Cấu hình MIG trên GPU Kubernetes service | |||
| Tại bước khởi tạo worker group GPU, bạn có thể chọn các profile MIG sharing mode trên giao diện và GPU Kubernetes service của chúng tôi sẽ thực hiện việc cấu hình cho bạn: | |||
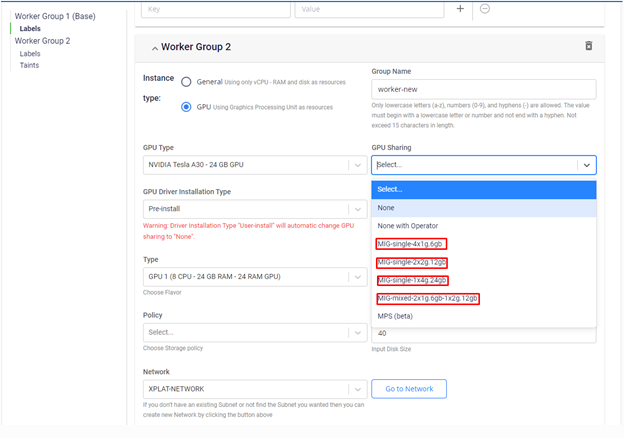 | |||
| Chú ý: | |||
| ✔ Nếu bạn chọn các profile có dạng “MIG single”, các worker group tiếp theo của bạn chỉ có thể chọn các sharing mode thuộc các profile dạng “MIG single”, tương tự với profile “MIG mixed”, “None”, “None with Operator”. | |||
| ✔ Sharing mode “None” tương ứng với việc chúng tôi để toàn quyền cụm Kuberntes GPU cho bạn, bạn có thể thực hiện cài thủ công GPU Operator hoặc Nvidia device plugin để chạy các sharing mode theo nhu cầu. | |||
| ✔ Sharing mode “None with operator” tương ứng với việc chúng tôi thực hiện manage GPU Operator cho bạn. Tuy nhiên thì 1 GPU sẽ chỉ được gán vào tối đa 1 container trong một thời điểm. |
- Verify MIG
Sau khi hệ thống portal của chúng tôi báo cụm ở trạng thái success, bạn có thể kiểm tra tài nguyên GPU của một node GPU bằng lệnh:
CopyKubectl describe nodes
Output:
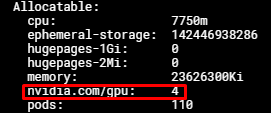 Lúc này, bạn có thể yêu cầu tối đa 4 tài nguyên nvidia.com/gpu cho pod của mình, mỗi tài nguyên nvidia.com/gpu tương ứng với ¼ khả năng tính toán và bộ nhớ của GPU vật lý ban đầu.
Trong trường hợp node của bạn sử dụng 2 GPU, sẽ có 8 tài nguyên nvidia.com/gpu được hiển thị.
Ngoài ra, bạn có thể kết hợp MIG với các chiến lược chia sẻ GPU khác như time sclicing (đã hỗ trợ) và MPS (chưa hỗ trợ) để tối đa hóa mức độ sử dụng GPU.
C. Multi Process Service (MPS)
✔ MPS là một tính năng trong GPU của NVIDIA, cho phép nhiều container chia sẻ cùng một GPU vật lý.
✔ MPS có ưu điểm hơn so với MIG về vấn đề phân chia tài nguyên GPU, tối đa 48 container có thể sử dụng GPU cùng lúc.
✔ MPS dựa trên tính năng NVIDIA's Multi-Process Service của CUDA, cho phép nhiều ứng dụng CUDA chạy đồng thời trên một GPU.
✔ Với MPS, người dùng có thể xác định trước số lượng replicas của một GPU. Giá trị này cho chúng ta biết số lượng container tối đa có thể truy cập để sử dụng một GPU.
✔ Ngoài ra, chúng ta có thể giới hạn tài nguyên GPU cho từng container, bằng việc tạo các biến môi trường sau trong container:
CUDA_MPS_ACTIVE_THREAD_PERCENTAGE
CUDA_MPS_PINNED_DEVICE_MEM_LIMIT
✔ Để hiểu rõ hơn về cách thức MPS hoạt động, vui lòng truy cập : https://docs.nvidia.com/deploy/mps/
Lúc này, bạn có thể yêu cầu tối đa 4 tài nguyên nvidia.com/gpu cho pod của mình, mỗi tài nguyên nvidia.com/gpu tương ứng với ¼ khả năng tính toán và bộ nhớ của GPU vật lý ban đầu.
Trong trường hợp node của bạn sử dụng 2 GPU, sẽ có 8 tài nguyên nvidia.com/gpu được hiển thị.
Ngoài ra, bạn có thể kết hợp MIG với các chiến lược chia sẻ GPU khác như time sclicing (đã hỗ trợ) và MPS (chưa hỗ trợ) để tối đa hóa mức độ sử dụng GPU.
C. Multi Process Service (MPS)
✔ MPS là một tính năng trong GPU của NVIDIA, cho phép nhiều container chia sẻ cùng một GPU vật lý.
✔ MPS có ưu điểm hơn so với MIG về vấn đề phân chia tài nguyên GPU, tối đa 48 container có thể sử dụng GPU cùng lúc.
✔ MPS dựa trên tính năng NVIDIA's Multi-Process Service của CUDA, cho phép nhiều ứng dụng CUDA chạy đồng thời trên một GPU.
✔ Với MPS, người dùng có thể xác định trước số lượng replicas của một GPU. Giá trị này cho chúng ta biết số lượng container tối đa có thể truy cập để sử dụng một GPU.
✔ Ngoài ra, chúng ta có thể giới hạn tài nguyên GPU cho từng container, bằng việc tạo các biến môi trường sau trong container:
CUDA_MPS_ACTIVE_THREAD_PERCENTAGE
CUDA_MPS_PINNED_DEVICE_MEM_LIMIT
✔ Để hiểu rõ hơn về cách thức MPS hoạt động, vui lòng truy cập : https://docs.nvidia.com/deploy/mps/
- Cấu Hình MPS trên FPTCloud K8s GPU service
Bạn có thể cấu hình cho worker group GPU của mình sử dụng GPU trong quá trình khởi tạo worker group như hình minh họa sau:
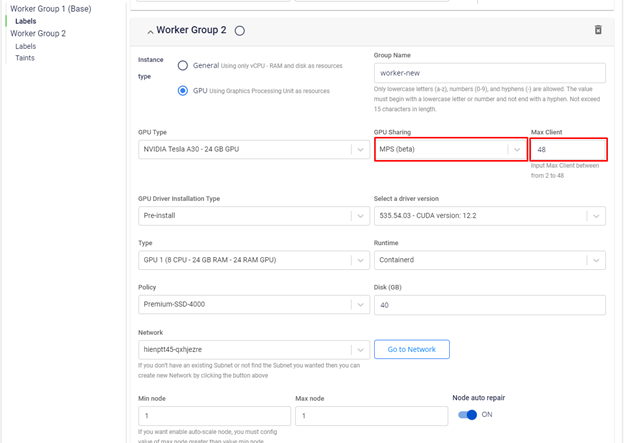 Với cấu hình này, GPU sẽ được "chia" thành 48 phần, mỗi phần mang khả năng tính toán và bộ nhớ bằng 1/48 GPU vật lý ban đầu
Với cấu hình này, GPU sẽ được "chia" thành 48 phần, mỗi phần mang khả năng tính toán và bộ nhớ bằng 1/48 GPU vật lý ban đầu
- Verify MPS
Bạn có thể kiểm tra cấu hình MPS trên node GPU của mình bằng lệnh:
Copykubectl describe nodes $NODE_NAME
Output:
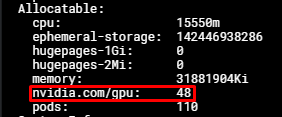 Lúc này, bạn có thể yêu cầu tối đa 48 tài nguyên nvidia.com/gpu cho các pod của mình, mỗi tài nguyên nvidia.com/gpu tương ứng với 1/48 khả năng tính toán và bộ nhớ của GPU vật lý ban đầu.
Trong trường hợp node của bạn sử dụng 2 GPU, sẽ có 96 tài nguyên nvidia.com/gpu được hiển thị.
Một vài lưu ý
Lúc này, bạn có thể yêu cầu tối đa 48 tài nguyên nvidia.com/gpu cho các pod của mình, mỗi tài nguyên nvidia.com/gpu tương ứng với 1/48 khả năng tính toán và bộ nhớ của GPU vật lý ban đầu.
Trong trường hợp node của bạn sử dụng 2 GPU, sẽ có 96 tài nguyên nvidia.com/gpu được hiển thị.
Một vài lưu ý
- Tài nguyên nvidia.com/gpu một container yêu cầu phải bằng 1.
- Số max client tối đa là 48, ít nhất là 2, tài nguyên GPU vật lý được chia đều cho các max client.
- Một container chạy một process để đảm bảo sharing mode MPS không phát sinh lỗi.
- Yêu cầu phần "hostIPC:true" tại file manifest triển khai workload.
- MPS có những giới hạn về error containment và workload isolation, hãy tìm hiểu và cân nhắc trước khi sử dụng.
D. Time Slicing ✔ Timeslcing là tính năng chia sẻ GPU nguyên thủy, từng prorcess/container được sử dụng GPU trong một khoảng thời gian giống nhau. ✔ Timeslicing thực hiện chia sẻ GPU theo cơ chế context switching trong CPU, mỗi process/container sẽ được lưu lại context khi GPU được sử dụng bởi process khác. ✔ Time slicing không hỗ trợ chia sẻ GPU một cách song song như MPS.
- Cấu hình Time slicing trên GPU Kubernetes service
Timeslicing là một tính năng chia sẻ GPU nguyên thủy, nó có thể được trên toàn bộ các MIG sharing mode (trừ các profile MIG-mixed), và mode “None with Operator”
Tại bước khởi tạo worker group GPU, bạn sẽ chọn kết hợp timeslicing với MIG hoặc dùng timeslicing trên GPU với MIG mode enabled, chúng tôi sẽ thực hiện việc cấu hình cho bạn:
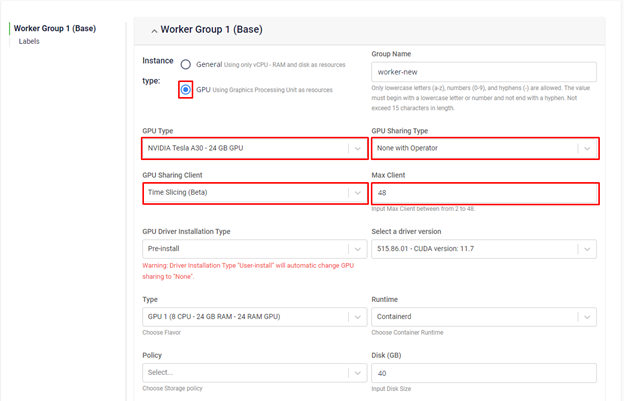
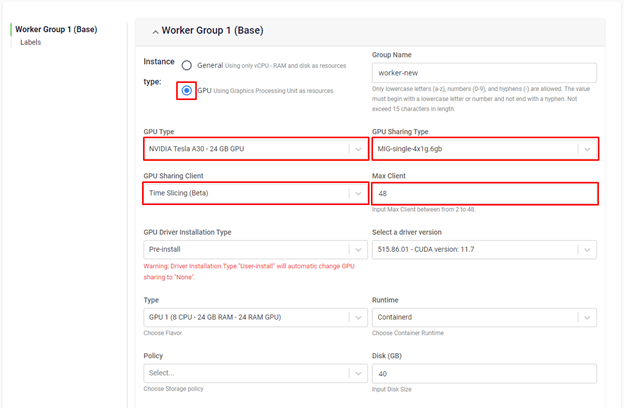
- Verify Time slicing
Bạn có thể kiểm tra cấu hình timeslicing trên node GPU của mình bằng lệnh:
Copykubectl describe nodes $NODE_NAME
Output:
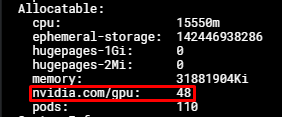 Lúc này, bạn có thể yêu cầu tối đa 48 tài nguyên nvidia.com/gpu cho các pod của mình. Tuy nhiên khác với MPS, mỗi pod không bị giới hạn về lượng tài nguyên nó được quyền chiếm, do vậy có thể dẫn đến tình trạng tràn bộ nhớ.
Trong trường hợp bạn sử dụng MIG mode, số lượng tài nguyên nivida.com/gpu bằng số lượng MIG instance * số lượng Time Slicing max client bạn định nghĩa. VD: bạn sử dụng MIG mode 2x2g.12gb và số timeslicing client bằng 48, sẽ có 96 tài nguyên nvidia.com/gpu được hiển thị.
Một vài lưu ý
Lúc này, bạn có thể yêu cầu tối đa 48 tài nguyên nvidia.com/gpu cho các pod của mình. Tuy nhiên khác với MPS, mỗi pod không bị giới hạn về lượng tài nguyên nó được quyền chiếm, do vậy có thể dẫn đến tình trạng tràn bộ nhớ.
Trong trường hợp bạn sử dụng MIG mode, số lượng tài nguyên nivida.com/gpu bằng số lượng MIG instance * số lượng Time Slicing max client bạn định nghĩa. VD: bạn sử dụng MIG mode 2x2g.12gb và số timeslicing client bằng 48, sẽ có 96 tài nguyên nvidia.com/gpu được hiển thị.
Một vài lưu ý
- Tài nguyên nvidia.com/gpu một container yêu cầu có thể bằng hoặc hoặc lớn hơn 1. Tuy nhiên yêu cầu nhiều hơn 1 tài nguyên nvidia.com/gpu không giúp cho container của bạn được quyền truy cập nhiều tài nguyên hơn.
- Khi bạn sử dụng timeslicing, container không bị giới hạn về việc sử dụng tài nguyên tính toán và bộ nhớ.
- Số max client tối đa là 48, ít nhất là 2.
- Một container chạy một process.
- Cần xác định rõ ràng lượng tài nguyên GPU container cần để tránh trường hợp OOM gây gián đoạn hoạt động của GPU.